
Secondary Advantages of using RAG
Retrieval-Augmented Generation (RAG) allows software engineers to overcome some of the more serious limitations when building LLM driven AI applications in the real world.

In some of my previous posts, I explored giving Large Language Models (LLMs) context using external data and vector stores. The posts focused on when to improve LLM performance by adding external context to prompts, instead of fine-tuning. External context can overcome limitations in terms of performance, costs and limited context lengths. The posts mainly explored how to use context to ground the LLMs.
Over the last few months the adopted term for providing LLMs with context from external data sources (normally using Vector Stores) has commonly been referred to as RAG (Retrieval-Augmented Generation). Libraries such as LangChain and LlamaIndex are normally used to facilitate building RAG solutions.
In this post I want to explore additional advantages of using RAG when building real world AI applications with LLMs. These secondary advantages solve issues such as user authorisation, dealing with stale data and privacy concerns when removing data.
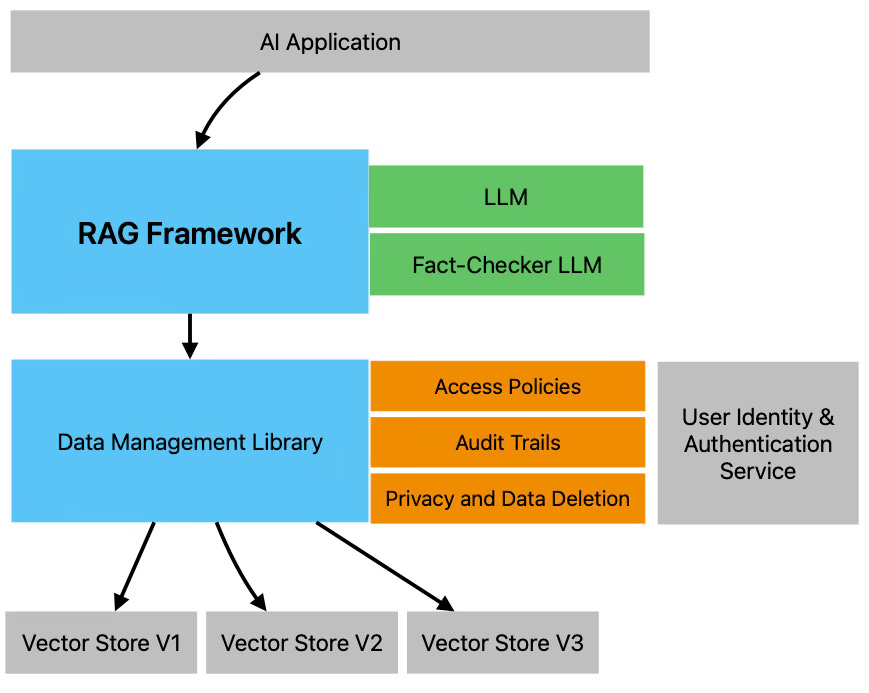
Data Access Rights & Policies
If a company decides to train / fine-tune an LLM using it’s corporate data (emails, documents, databases etc) and build a chatbot interface for it’s employees or clients - it will encounter a big issue. It is very difficult to engineer a system which will ensure LLM output takes into account user access right policies and authorisation.
Alternatively when adopting a RAG technique - documents and data would normally be stored in a Vector Database. The records in the databases would be assigned UUIDs which can then be referenced against an authorisation module for the current user. The search query could be modified to only retrieve authorised records, or alternatively unauthorised data can be filtered out after the query before building the LLM prompt.
Using this method, only content from authorised documents / data sources will be sent as context to the LLM, and the output will reflect this. In addition, it is easy to modify access policies for groups and users dynamically, or change access rights on specific data easily without needing to retrain or fine-tune your models.
Citations and references
Another advantage of RAG, is the ability to store metadata alongside the data records in your vector databases. This metadata could include the original source and author of the data (for example the source document, email, chat etc.).
This allows engineers to reference this metadata before sending the context to the LLM. If the LLM chooses to use any information from this context in its output, it is easy to annotate citations or data sources alongside the output.
Checking for hallucinations
In a similar technique to inserting references and citations, RAG is useful to reduce hallucinations. Once the context is retrieved from the vector databases and sent to the LLM, the output of the LLM can then be cross referenced against the context data to check for hallucinations.
A secondary ‘fact-checker’ LLM can be used to do this. The ‘fact-checker’ is given the same context as well as the original output from the LLM and it is asked to evaluate the factuality of the output with respect to the context.
If the original output also generated additional information, which was not provided in the context, then the ‘fact-checker’ LLM could generate additional queries to the Vector Store to try and find relevant information which could verify the output.
If the ‘fact-checker’ LLM gives a low evaluation of the accuracy / factuality of the data, then the original output is discarded and the main LLM is prompted to regenerate and the evaluation criteria is satisfied.
Removal of stale data / adding new data
Corporate data is constantly changing. Old data can become stale or obsolete and new data should be given a stronger weighting.
Once again with training / fine-tuning LLMs, the engineers would need to prune and update the training data and then undergo the expensive and slow process or training from scratch.
With RAG is it is easy to keep the Vector Stores up to date by pruning old data and inserting new data. In addition, it is also possible to use the meta-data alongside each record to give the data a weighting based upon its age or ‘freshness’. For example if the context data being stored in the Vector Data contains news articles or ‘memories’, it is possible to use time-to-live (TTLs) or age values and then use the queries to prioritise newer or fresher data if multiple similar documents exist.
Forgetting Data / Privacy / Copyright issues
The above becomes even more important in situations where the administrator of the model is forced to remove information from the Large Language Model within a given timeframe. These include privacy or copyright scenarios. When adopting a RAG approach, forgetting information is a simple matter of deleting records from the Vector Stores in a similar approach to managing data in traditional database systems.
New methods to get an LLM to ‘forget’ subsets of it’s training data are being researched, but they are still expensive and the opaque nature of the LLM’s parameters makes it difficult to confirm that the data has really been forgotten.
Audit Trails
In traditional database systems, document management systems and knowledge-bases we are used to having audit trails. These audit trails allow system administrators to report on who accessed data, what they accessed and when they accessed it.
By using RAG, the system can audit which vector store records were accessed and injected into each prompt. The user that initiated the request can also be logged and the output generated by the LLM can be stored on the audit trail.
This gives a level of transparency and audit that cannot be achieved when using LLMs without RAG.
Versioning / testing & deploying AI systems
When an AI system is designed to take advantage of a RAG approach, it leads to easier management, testing and deployment of new versions of the system.
New versions of the RAG data stores can be made available to a smaller cohort of test users before being more widely distributed. The content of the vector stores is transparent and can be compared to previous versions easily.
It is also easier to manage different versions of different stores for different user groups, languages, regions etc.
For most software engineers, experienced in building traditional SQL or NoSQL database solutions, the testing and deployment procedures that they are familiar can continue to be used.
In conclusion
Retrieval-augmented generation (RAG), has become popular because it is a feasible way to ground LLMs and increase performance on certain tasks, personalise them to user data and overcome cost and context length limitations.
Secondary advantages when using RAG techniques are equally important as they solve some of the biggest issues that engineers are encountering when building AI applications in the real world.