


Leveraging Large Language Models in your Software Applications

How can you leverage the capabilities of Large Language Models (LLMs) within your software applications?
You cannot simply create a thin application layer above an LLM API. Instead you need to design and build a number of components to ‘tame’ the underlying models and also to differentiate your product.
Over the last few months, a number of techniques and approaches have emerged on how to ground LLMs to your application’s use cases, data and user sessions. Other techniques can be used to maintain memories and states of previous interactions with the user, or to breakdown objectives into smaller tasks and subtasks.
This is not a detailed technical guide on how to implement and execute these techniques. Instead, I try to explain how these different components can be combined into an architecture to build AI software on top of LLMs. To help demonstrate, I also use a fictitious ‘fitness application’ as an example.
First of all, let’s understand the pitfalls of simply building a thin application layer on top of an LLM:
Responses to your user will be unpredictable and will contain hallucinations.
The responses will not be grounded to your application’s data and use cases.
You will not create a defensive moat around your product. Anyone can easily achieve the same results. Instead use your proprietary data and knowledge to build a defensive moat as described below.
High LLM API Costs. These costs can be significant, so you need to mitigate unnecessary calls and use cheaper models when possible.
LLMs are stateless and do not have agency. You need to iteratively orchestrate and automate the underlying LLM to improve task planning and reasoning capabilities.
At this stage, it is also good to note that new frameworks (such as LangChain), offer structured approaches to building applications around LLMs. This post does not explore these frameworks, since it only attempts to explain the high-level concepts.
I also suggest reading my previous posts on grounding LLMs and giving them context.
When should you use LLMs in your applications?
Use LLMs for language understanding and processing (not as knowledge sources)
LLMs are pretrained on a large corpus of text data from the internet. This training data gives them knowledge. It also allows for generalisation to a wide range of tasks which can then be fine-tuned downstream.
When building AI software it is tempting to simply use these LLMs as knowledge / fact sources (i.e. search engine). Instead, you should leverage the LLM for its powerful language understanding and processing. This will allow it to ‘understand’ user requests and provide ‘responses’. It should be provided with the knowledge and data related to your software application, and it should only return facts / information from the data that you provided.
LLMs can also be used for basic reasoning
In addition to language understanding, some LLMs also offer decent performance when it comes to basic reasoning. Especially when prompted to work step by step. This can allow you to leverage LLMs to break down user requests / responses into smaller tasks.
Use LLMs for review, evaluation and feedback
LLMs are much more effective at reviewing text and reporting issues in it, than generating text from scratch. Therefore use this technique as much as possible. Send an LLM’s output back to the LLM and ask it to double check it’s output iteratively.
Use LLMs for text transformation, expansion, summarisation
Convert unstructured text to JSON format and vice versa, expand short text and summarise long text.
High level architecture diagram
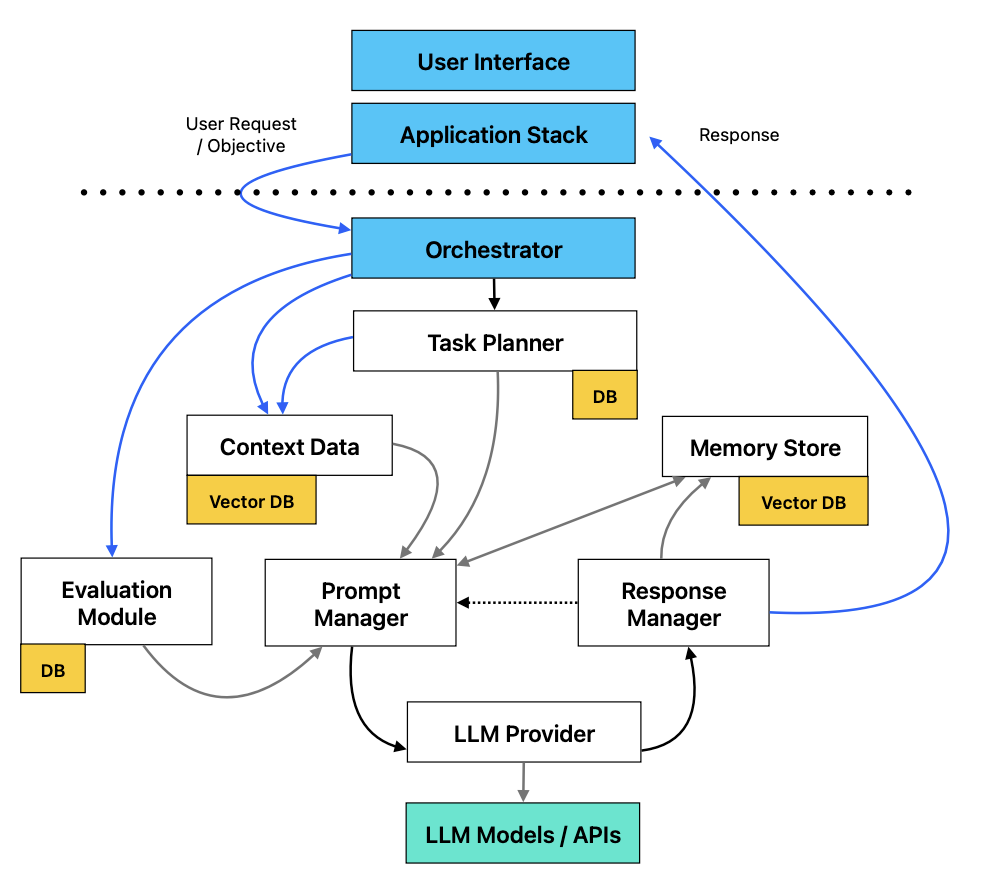
The main components of the architecture are listed below, and illustrated in the diagram above. The following sections dive into a detailed explanation of each component.
Orchestrator
LLM Provider
Task Planner
Context Data Vector Store
Memory Data Vector Store
Prompt Manager
Response Manager
External Tool Provider
Prompt & Response log
Evaluation Module
Orchestration & Multi-tenancy
The orchestrator simply sits under the Application Stack and chains the other modules together.
If you are developing a website or an application that will be used by multiple users, then it is important to build multi-tenant components.
This will ensure:
Personalisation for each user
Privacy, to ensure that memories, context etc. are only retrieved for the correct user.
Each of the modules listed below will need to be designed as multiple multi-tenant instances.
LLM Provider
Different types of LLM models exist, each having their own strengths and weaknesses. You need to make use of multiple LLMs for your application to take advantage of this. When choosing which models to use take into account the following:
LLM inference costs / API cost considerations
Encoder only (eg. BERT) vs Decoder only (eg. GPT) for different use cases. For example you can use Encoder models for sentiment analysis and Decoder models for text completion or chat.
Text embeddings models for semantic search and generating vector embeddings (more about this later)
Smaller, faster, cheaper models for basic text manipulation. Larger, more expensive, slower state of the art models for basic reasoning and text generation.
Fine-tuned models for better performance on a specific task
Instruct models fine-tuned to act as an assistant in chat mode (eg. ChatGPT uses RLHF)
An LLM provider would allow you to choose which model to use for each request. The output of one request, can be chained into a second model for text manipulation or review.
For example, you could use GPT-4 when important reasoning tasks are required, and then use GPT-3 for basic text manipulation or completion.
Doing this properly will help control API costs and also ensure that the best suited model is used for each request. You can use open source cheaper models for certain tasks; especially if their output will not be sent directly to the user interface.
By building a provider, the differences between APIs and model usage can be abstracted from the rest of the application. It also allows for a plugin approach to LLMs, allowing new models to be introduced easily.
Task Planner
A nice approach is to obtain the user’s request / objective and use a model to break this down into subtasks. Each subtask can be further broken down into smaller tasks / objectives depending on the application.
This would be an ongoing process, and as the user moves through objectives, then the LLM can be used to expand current tasks and subtasks, or prune the ones that are no longer necessary.
A number of frameworks and open source projects offer this type of functionality. The most popular example is AutoGPT.
You could approach this as follows:
Get user objective and send to an LLM with good reasoning capabilities (eg. GPT-4)
Prompt the LLM to break down into subtasks and return as a JSON list
Save subtasks into a database.
Depending on the application, you can update the user interface based on the subtasks.
Iterate into smaller sub-tasks as needed.
An example of how this would work in the fitness application.
The user specifies their workout / health objectives and constraints
The context data vector store is queried to retrieve appropriate workout routines, health & nutrition information, equipment required etc. based on user context (explained in next section).
An LLM is used to generate a workout and health routine based on retrieved context data.
The LLM is asked to breakdown the workout into top level routines (eg. daily workouts, meal plans) and return this in a specific JSON format.
The routines are stored in a database and used to update the UI (enforced JSON format allows for UI updates)
Each top level routine is sent to the LLM, which is in-turn asked to generate the subroutines for that daily workout.
Once again these subtasks are saved to the database and used to update the user interface.
The routines and the subroutines now form the Task Planner which will drive the application / user session going forward.
Context Data Vector Store
As mentioned in the introduction, we should not use the pre-trained LLM knowledge for our application. Instead we should prime each prompt with any necessary context information and specify that the LLM only responds based on information included in the prompt.
This will ensure that the responses are grounded to your application and use cases. By using vector embedding and vector databases, you can semantically retrieve subsets of your context data for each prompt, allowing for better efficiency, performance and lower costs.
I describe using semantic search and working with context data and vector databases in this article.
The approach is as follows:
Whenever you have new context information, chunk it into sections and use an LLM to generate vector embeddings. Next store the embeddings in a vector database. You will also store additional information alongside each embedding (eg. URLs, images, source text etc.)
Before sending a request to an LLM, always send the request as a query to the Vector Store first. Get the top N relevant results and add them to the request prompt. Specify that the LLM should only use information from the prompt. Submit the prompt.
When you receive the response, compare it to the context data you sent. Ensure that there are no hallucinations and that it is grounded to your data.
This can be done iteratively, where the response is used to generate a new query to the vector database, and the results are then used for the next prompt to the LLM.
It is also possible to ask the LLM to generate a query to the vector store if it needs additional information.
It is also important to note that the records received from the vector database will also contain additional data besides text. These could be images, urls, video urls etc. You can augment your responses to the user interface with this information.
Fitness Application Example
Your proprietary corpus of workout, health and nutrition text data is converted into vector embeddings and stored in a vector database.
When the user sends a workout / health objective, it is converted into a text query and used to query the vector database.
The most relevant (semantically) workouts, health information etc. are retrieved and encoded into the prompt.
The LLM is then prompted to generate a workout and health plan based on information provided in the prompt (only) and user objectives.
The response is then used to build the task planner (see previous section).
Relevant images, videos, URLs can also be used to augment the text returned by the LLM. In-turn these will be displayed in the user interface.
Memory Vector Store
The memory vector store is similar to the context data store, but it is populated by LLM prompt and response pairs generated during previous usage of the application.
The objective here is to allow the LLM to refer to previous interactions in order to personalise it to the user and steer it in the correct direction.
The memories can also be tagged using timestamps, locations etc. to allow for filtering or relevant memories and fading (i.e. pruning) of older memories.
Using the fitness application example:
A request is prepared based on a user’s action in the UI. The request is converted to a vector embedding and sent to the memory vector store to retrieve any relevant ‘memories’.
A memory might consist of a particular interaction. For example a comment by the user stating that they cannot do a particular workout due to an injury. Or perhaps that they don’t like a type of food.
The memories are then added to the prompt along with the user request and any context extracted from the context store. In the prompt, the memories would be prefixed by text along the lines of “Here is a list of previous interactions, take these into account when responding to ensure that you adhere to previous requests and preferences.”
The prompt is then sent to the LLM in the usual manner.
The prompts and responses that are generated during the current session are then converted into vector embeddings and stored in the memory vector store. They will be retrieved whenever they are semantically relevant to future LLM interactions.
Prompt Manager
The prompts that we are discussing above are lengthy and complex. The best approach is to build a prompt manager which can accept a number of properties and build the prompt in the correct structure.
The prompts will loosely take this form:
{{System Message}}
eg. You are an expert nutritionist and a helpful personal trainer
{{ Request Text }}
eg. I need to lose weight and lower my cholesterol level. I also want to be able to run 10km.
{{ Context Header }}
Eg. Only respond using information provided in the context information below. If there isn’t enough information below to respond accurately, then respond with ‘I need more information related to {query message}.’
{{ List of Relevant Context Information }}
{{ Memory Header }}
Eg. We have had the following relevant interactions previously. Please refer to these interactions and ensure that you adhere to my previously stated preference and requests.
{{ List of Relevant Memory pairs }}
{{ Response format requirements }}
Eg. Explicit JSON FormatNote about Response format requirements
In order to be able to use the response in your application, it is important that you can predict the format that you will receive. The best approach is to provide the expected JSON format in the prompt. This JSON format can include properties such as UI elements to modify, actions to take etc.
Actions can sometimes be mapped by the LLM automatically. For example, if you would like the user’s request to be translated into specific UI actions, you can provide the following information in the prompt:
“Map the user’s request into one of the following actions. ‘PREVIOUS’, ‘NEXT’, ‘CLOSE’, ‘REPEAT’, ‘EXPAND’, ‘NO ACTION’. If you are unable to map accurately then respond with ‘UNKNOWN’.
Response Manager
The response manager is similar to the prompt manager, but it will validate and verify the response instead. It can handle the following:
Check response format to ensure that it adheres to requirements sent in prompt. (Eg. Verify JSON Format)
Validate the response against the loaded context and memory data to ensure that it is not hallucinating.
Send the response back to an LLM along with the original prompt and ask the LLM to decide if we have a good quality response or not.
Check the response for undesired content, negative sentiment etc.
If the response manager does not approve the response, then it can generate a new prompt with the reasons for the rejection and submit it to the LLM to get a new response.
This can take place iteratively until the response meets all criteria and safety checks.
Evaluation Module
LLMs can be good at evaluating a user’s prompt and rating it according to predefined criteria.
An example related to the fitness application would be that the user is prompted to provide feedback after completing a workout or daily routine.
The LLM can then be prompted to evaluate the feedback on criteria such as:
Did the user report any pain? (-1=unknown, 0=no pain, 10=severe pain)
Did the user enjoy the workout? (-1=unknown, 0=not at all, 10=a lot)
Does the user feel that they are reaching their objectives? (-1=unknown, 0=no, 10=fully reached)
Etc.
The LLM would return the feedback in JSON format and the evaluations can be stored in a database. You can then use these to build out new features such as:
Show automatic evaluation ratings along side workouts in the UI
Use evaluations to improve your context data
Use evaluations to update the Task Planner and expand, collapse, prune future planned workouts
External tool provider
LLM capabilities can be extended by providing access to external tools, such as calculators etc. My current thinking is that it is better to use the external tools from the rest of your application layers and not allow the LLM to access the tools directly.
An obviously example is when your application needs to perform calculations. This should be done by the application and not by giving the LLM access to a calculator plugin.
That being said, I think it is important to note that an External Tool provider could be a essential component in this high level architecture.
Prompt & Response Application Log
An obvious component would be an application log of all interactions with LLMs. The LLM responses are not deterministic and cannot be predicted. Therefore during debugging, it is important to be able to view the exact responses from the LLM.
The log can be extended to store the LLM model version, api costs, response times etc.
The memory vector store is not a substitute for this, since the memories are stored as vector embeddings and cannot easily be used as a log.
Note about privacy and security
This post does not address privacy and security concerns when building applications on top of LLMs. New threats such as prompt injection and privacy concerns when using third party LLMs need to be addressed.
In conclusion
A thin application which simply forwards user requests to an LLM and returns the response to a user, can easily be copied and will prove to be unreliable.
By designing the correct architecture, leveraging a pool of LLMs with different capabilities and grounding them to your data and context - you can quickly build powerful applications. These applications will possibly overcome LLM limitations such as response times, high costs, hallucinations and offer reliability to your users.
Hopefully this post was effective in explaining these high level concepts and techniques, and exploring how they could be combined. I plan to dive deeper into key parts of this architecture with technical articles in the future.